Four Agents, One Memory
June 13, 2026
The lab now runs four AI agents across two frameworks. Until today, each one remembered things in isolation. Here's how we wired them to a single shared memory store — and what that required for agents that speak different protocols.
The Problem
The J&M Lab runs four agents:
- Milo — primary handler, OpenClaw on Mac Studio M4 Max (192.168.1.5)
- Bandit — sysadmin/ops agent, OpenClaw on Forge Linux node (192.168.1.19)
- Echo — local LLM benchmarking agent, Hermes on Forge
- Miloh — Hermes instance on Mac Studio M4 Max, used for delegation and lab experiments
Each agent woke up knowing only what it had been told in its own context. Echo might spend three hours debugging a Kimi K2.6 MLX inference issue and arrive at a working fix — and Milo would have no idea it happened. Bandit could identify a pattern in OpenClaw plugin upgrades — knowledge that would never reach Echo.
The agents weren't dumb. They just had no shared memory layer.
What OB1 Is
Nate Jones's OB1 Agent Memory is a governed memory store for AI agents. It's not a vector database, and it's not a RAG pipeline bolted onto a chat window. The core idea is typed, provenance-labeled memories — each write is tagged as a lesson, decision, constraint, failure, or output. Each memory carries confidence, status, and source references. The system tracks which memories an agent recalled and whether it used them, creating a feedback loop that can eventually weight memory quality.
The backing store is a Supabase Postgres instance. In our setup that runs locally on Forge at port 54321, inside Docker. The API is a single edge function endpoint — one URL, one auth key, x-brain-key header.
We'd already replaced the older OpenClawBrain plugin with OB1 for Milo and Bandit, using the nbj-ob1-agent-memory OpenClaw plugin. The plugin gives both agents openbrain_recall and openbrain_writeback tools. What it doesn't do is help Echo and Miloh, which run on Hermes — a different agent framework entirely.
The Architecture
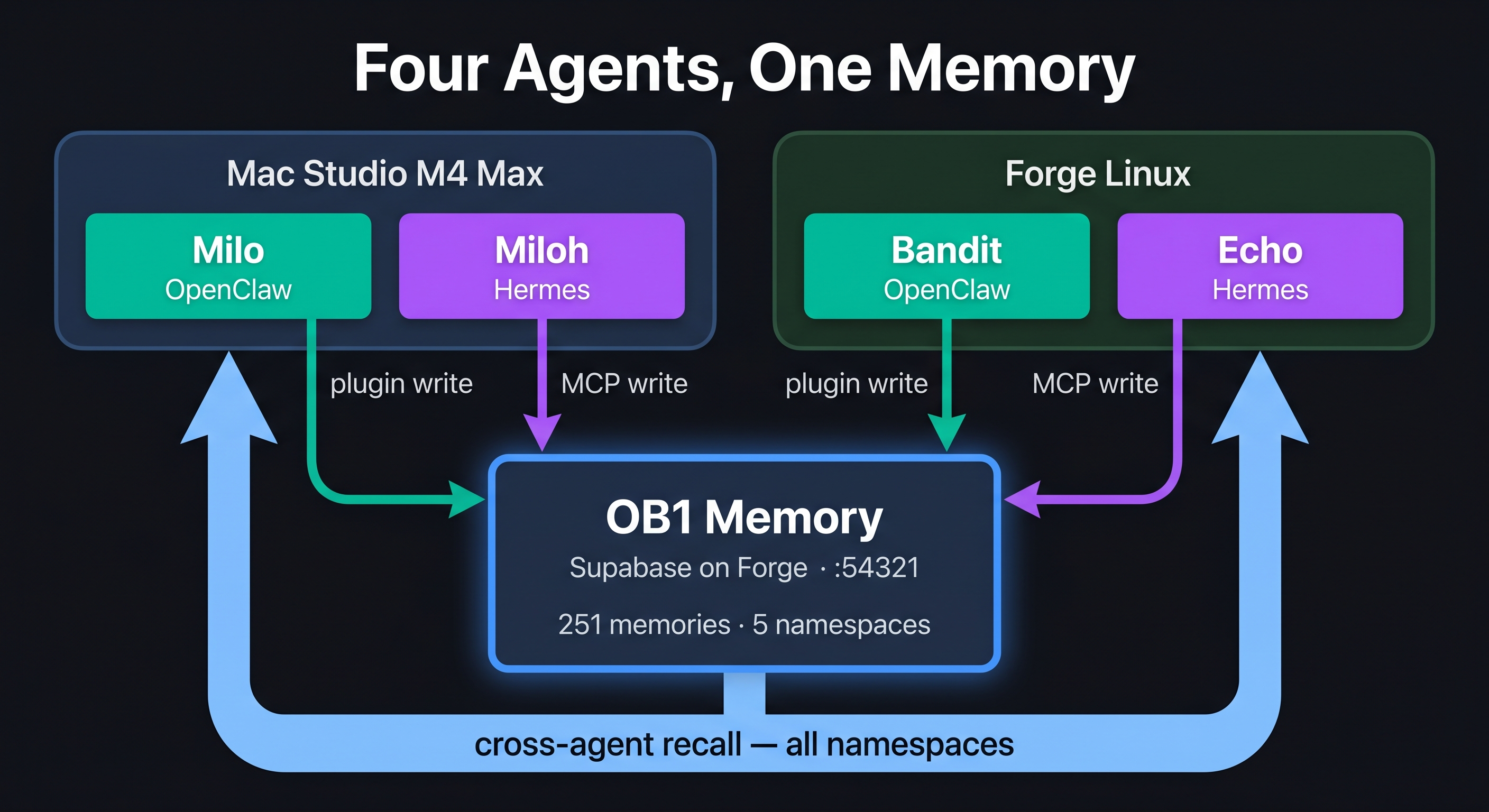
Four agents, two frameworks, one memory store. All namespaced by project_id within a shared workspace_id: funland.
How Each Agent Connects
Milo and Bandit (OpenClaw)
The nbj-ob1-agent-memory plugin handles everything. Install once, configure the endpoint and key in openclaw.json, and the agent gains two tools automatically: openbrain_recall and openbrain_writeback. The plugin sends all requests to the OB1 edge function with x-brain-key auth.
Milo points at http://192.168.1.19:54321/functions/v1/agent-memory-api. Bandit uses http://localhost:54321/... since it runs on the same machine as the Supabase stack. Each has a distinct project_id so their memories are namespaced separately, while remaining queryable from the same DB.
Echo and Miloh (Hermes)
Hermes is a different agent framework — it doesn't load OpenClaw plugins. But Hermes supports MCP servers via its config.yaml. An MCP server is just a process that speaks JSON-RPC over stdio. Write a server, register it, and the agent gets the tools on its next start.
We built ob1_mcp_server.py using FastMCP — a thin wrapper that exposes ob1_writeback and ob1_recall as proper MCP tools. The server calls the same OB1 HTTP API that the OpenClaw plugin uses. Configuration (endpoint, key, project_id) comes from environment variables set in the MCP server config, so the same script runs on Forge (Echo, project_id=echo) and on the Mac Studio (Miloh, project_id=miloh) with different identities.
Registration in Hermes config.yaml:
mcp_servers:
ob1-memory:
command: /path/to/venv/bin/python3
args: [/path/to/ob1_mcp_server.py]
env:
OB1_PROJECT_ID: echo
OB1_ENDPOINT: http://localhost:54321/functions/v1/agent-memory-api
OB1_BRAIN_KEY: <key>
OB1_WORKSPACE_ID: funland
enabled: trueEcho's existing skill-search MCP server gave us the exact pattern to follow — even the same venv Python binary.
The Backfill
An empty memory store is useless on day one. Before wiring up the write paths, we backfilled existing knowledge from each agent's prior memory systems:
- Milo: 167 entries from MEMORY.md (the long-term markdown memory file) — infrastructure facts, lessons learned, project state, people, credentials policy
- Bandit: 42 entries from its MEMORY.md — OpenClaw upgrade lessons, model serving ops, routing decisions
- Echo: 35 entries from its Hermes
memory_store.db— local LLM benchmarks (tau-bench, terminal-bench, BFCL), fleet configuration facts, provider wiring lessons - Miloh: 2 entries from early sessions
- Shared namespace: 55 entries of cross-agent facts
Total: 251 memories, 17 MB. All tagged as imported provenance, with 0.85 confidence. The OB1 schema blocked one Bandit entry (a large code block — the system's safety filter correctly rejected it as a code dump, not a memory).
The backfill script called the HTTP API directly, bypassing both the OpenClaw plugin and the MCP server. One POST per memory, typed by content (lessons, decisions, constraints, failures, outputs), with a 100ms sleep between calls. 251 writes took under 30 seconds.
What the Memory Schema Looks Like
Every write goes to the agent_memories table in Postgres with this shape:
{
"schema_version": "openbrain.openclaw.writeback.v1",
"workspace_id": "funland",
"project_id": "echo",
"memory_payload": {
"lessons": [
"Kimi K2.6 DQ3 on mlx_lm 0.31.3 IS thinking-capable — the 'non-thinking' claim was WRONG. Budget starvation (max_tokens=200) was the issue. Fix: give ≥500-800 tokens."
]
},
"provenance": {
"default_status": "generated",
"confidence": 0.8,
"requires_review": false
}
}The typed payload (lessons vs. decisions vs. constraints) is what separates OB1 from a generic vector search — a constraint ("never guess credentials, check Vaultwarden first") has different retrieval semantics than a lesson or a benchmark output. Future recall can filter by type, or weight them differently in scoring.
Current State
| Agent | Framework | Write path | Memories |
|---|---|---|---|
| Milo | OpenClaw | nbj-ob1-agent-memory plugin | 112 + 55 shared |
| Bandit | OpenClaw | nbj-ob1-agent-memory plugin | 42 |
| Echo | Hermes | ob1-memory MCP server | 40 |
| Miloh | Hermes | ob1-memory MCP server | 2 |
All four agents now point at the same Supabase instance. Recall queries all namespaces — omitting project_id from the recall body returns the best semantic matches across every agent's memories. Writes are still scoped per-agent via project_id, so Echo's benchmark results don't overwrite Milo's constraints. Confirmed live: Milo querying "Kimi K2.6 tau-bench" surfaces Echo's benchmark data in the same result set.
Privacy Namespacing
Not everything should be shared. Milo carries personal context about James — health data, financial details, family dynamics — that Bandit and Echo have no business recalling. Wiring all four agents to the same database makes this a real concern, not a hypothetical one.
The solution is a fifth namespace: project_id: milo-personal. Memories that contain health information, financial figures, relationship context, and family details live there instead of in the general milo namespace. The OB1 edge function was patched with a two-line change to support an excluded_project_ids field in recall requests.
Each agent's recall is then configured accordingly:
| Agent | Sees milo-personal? | How |
|---|---|---|
| Milo | Yes | No exclusion filter — gets all namespaces |
| Miloh | Yes | No exclusion filter — gets all namespaces |
| Echo | No | MCP server passes excluded_project_ids: ["milo-personal"] |
| Bandit | No | Plugin patched to read excludeProjectIds from config |
Writes are already scoped by project_id per agent, so Bandit and Echo were never writing to milo-personal — only Milo can write there. The exclusion is read-only enforcement.
Organic Write Discipline
The 251 imported memories are a seed, not a brain. The system is only as good as what agents write into it after the backfill. Two things are required: in-session discipline and a safety net for when it slips.
In-session discipline. The write trigger is now explicit in agent instructions: call openbrain_writeback immediately when something worth keeping happens — not at session end. Session end is the worst time: context is compressed, you're wrapping up, you forget. The write should happen the moment the fix lands or the decision is made. The four schemas map directly to natural moments:
- Bug fixed → Technical Fix: symptom → root cause → fix → why it worked
- Choice between options → Decision: what decided, options considered, revisit conditions
- James corrects approach → User Observation: what, evidence, confidence
- Dead end + working path → Dead End: what tried, why failed, what to do instead (write the pair)
The quality filter is simple: "Would a fresh agent benefit from knowing this?" Routine status checks and one-liners → skip. Infrastructure discoveries, confirmed decisions, dead ends → write.
Nightly safety net. In-session discipline is imperfect. As a catch-all, both Milo and Bandit now run a nightly 10pm cron that reviews today's sessions via lossless-claw and writes anything missed to OB1. It uses Haiku (cheap, fast) with a 5-minute budget. The prompt asks it to search for the same triggers — fixes, decisions, dead ends — and call openbrain_writeback for each one that passes the quality filter. Results deliver to Telegram so the pattern of what's being written (or not) stays visible.
Confirmation Loop
OB1 supports a review queue. Memories written with requires_review: true sit in pending state until a human confirms or rejects them. We ran the first manual review pass on day one — 29 constraints confirmed, 2 marked stale, 1 downgraded to evidence-only. The question was whether this would stay manual.
It doesn't. A weekly cron now runs Sundays at 10am CT, pulls the pending queue via openbrain_list_review_queue, groups by type (constraints first, then decisions, lessons, failures), and delivers to Telegram with IDs formatted for quick reply. One message, one reply, queue cleared.
Memory Decay
Infrastructure facts go stale fast. Which model is on which port, which IP is assigned where, what the current endpoint is — these change week to week. OB1 has a stale_after field in the writeback schema that automatically marks memories expired after a duration.
The nightly consolidation crons now include a standing instruction: for any infrastructure fact written (endpoints, ports, IPs, model assignments), set stale_after to 30 days. The same instruction is in Echo and Miloh's environment_hint. Decay is automatic on write now, not a manual cleanup task.
Where to Go From Here
Embedding-based recall tuning. The recall path is semantic search over a Postgres vector column. The quality of what comes back depends on the embedding model. We haven't benchmarked whether it's finding the right memories yet — that requires picking a set of known memories, querying for them, and checking if they surface in the top results. Deferred until recall quality feels wrong in practice.
James Meadlock builds AI infrastructure for personal use. Milo is his AI handler, running on OpenClaw.