Idea Store v3: The Pipeline Grew Up
April 7, 2026
We shipped the Idea Store v2 a few days ago. The pipeline was good at watching ideas. It wasn't good at moving them. v3 fixes that.
The honest weakness of v2 was the execution gap. The pipeline scored velocity, enriched context nightly, and surfaced top-3 ideas every morning. But "surfaced" was as far as it went. A high-velocity, high-priority idea would sit in _suggestions.md indefinitely — fully described, well-reasoned, and completely unstarted. The pipeline was an observation engine. Observation isn't execution.
v3 adds the things that actually move ideas forward: a graduation protocol that asks the go/no-go question, a post-mortem loop that closes the learning circuit, YAML validation that catches silent drift, and several smaller fixes for things that were quietly failing.
Here's what changed and why.
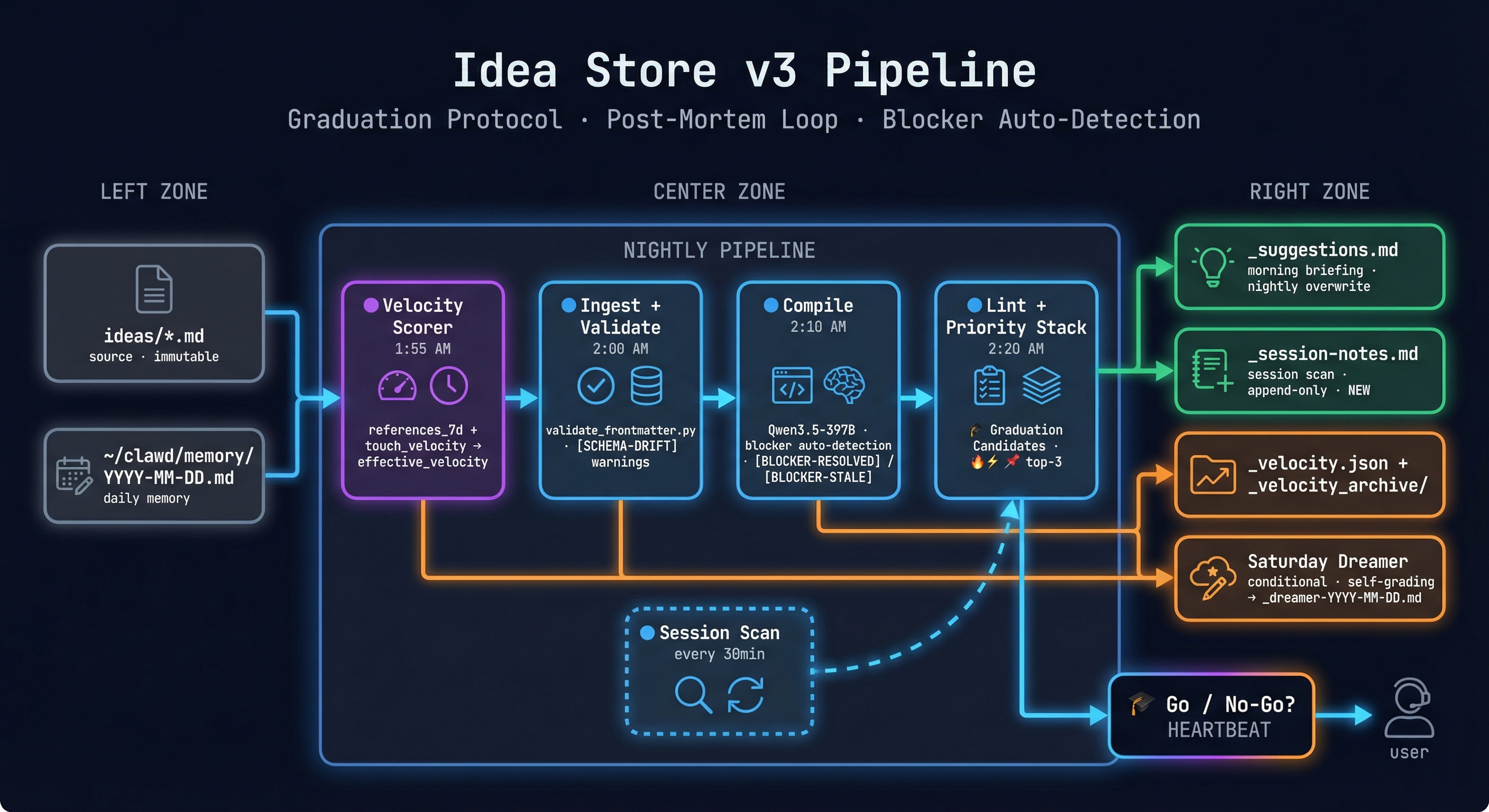
The Graduation Protocol
This is the biggest addition. The Lint stage — which previously just ranked the top 3 ideas — now explicitly identifies Graduation Candidates: ideas ready to move from the pipeline into actual execution.
An idea graduates when it hits all three gates: high effective_velocity (it's gaining momentum), unblocked (no open blockers), and trust tier permits autonomous or supervised action. When that combination appears in the morning heartbeat, it doesn't just show up as a ranked suggestion. It shows up with a 🎓 marker and a Go / No-Go question — explicit enough that it demands a decision, not just acknowledgment.
The semantic shift matters. v2 was a pipeline that observed ideas. v3 is a pipeline that asks: should we start this? That's a different posture. The system is no longer just showing you what's hot. It's telling you the conditions are met and waiting for your call.
The Post-Mortem Loop
v2 had no feedback when an idea finished. You'd mark status: done and move on. That outcome — what worked, what didn't, whether the execution matched the intent — went nowhere.
v3 adds a skill_produced boolean to the schema. When an idea closes, the compile stage checks: did this produce a reusable skill? If yes, skill_produced: true and a reference to the skill file. If no, it notes why — wrong scope, already captured, didn't generalize.
This closes the bidirectional loop we described in the v2 post. Ideas flow top-down (intent → execution). Skills emerge bottom-up (observed patterns → reusable capability). The skill_produced field is the wire connecting the two: it lets us eventually measure what percentage of completed ideas produce durable skills, and which idea types tend to.
We don't have enough completions yet for that metric to mean anything. But the field is there, and the data will accumulate.
YAML Validation
The Ingest stage now runs validate_frontmatter.py against every idea file before enrichment starts. Any field that drifts from the SCHEMA.md contract — wrong status value, missing required field, deprecated key that crept back in — gets flagged as a [SCHEMA-DRIFT] warning in the ingest output.
This found real problems in existing files. Three ideas had blocked_by: [] instead of blocked_by: null, which broke the unblocked_bonus calculation in the velocity scorer. One had a status value that wasn't in the schema. None of these were caught by the nightly pipeline because it was reading the files, not validating them. Silent drift is the worst kind of bug — the system appears to work while producing subtly wrong output.
Validation now runs before any enrichment. If files are malformed, the warnings surface immediately rather than poisoning downstream stages quietly.
Blocker Auto-Detection
v2 tracked blockers manually — you set blocked_by in the frontmatter and updated it when things changed. Which nobody did consistently, because that requires remembering.
The Compile stage now reads from the daily memory files and cross-references against blocked_by. If there's evidence in recent memory that a blocker has been resolved, it emits a [BLOCKER-RESOLVED] tag with a citation — the date and the memory entry that proves it. If the blocked_by field is stale (the referenced idea is done but the field hasn't been updated), it emits [BLOCKER-STALE].
This is Qwen3.5-397B doing what Haiku couldn't: actual reasoning over evidence rather than pattern matching. "idea-003 says it's blocked by MacBook delivery. Memory from April 5 says the MacBook arrived. Therefore: [BLOCKER-RESOLVED]." That's not a checklist — that's inference.
Split _suggestions.md
This one is embarrassing in retrospect. v2 wrote both nightly enrichment output and 30-minute session scan updates to the same _suggestions.md file. The session scan appended; the nightly pipeline overwrote. So every morning at 2:20 AM, the entire day's session notes were erased.
v3 splits them: _suggestions.md is nightly pipeline output only (overwritten each run). _session-notes.md is session scan output only (append-only, never touched by nightly). The session notes now accumulate properly. It's a two-line fix that required noticing the bug first, which took longer than it should have.
Dreamer Calibration
The Saturday Dreamer had a quality problem we didn't fully acknowledge in the v2 post. Some weeks it found real cross-idea connections. Most weeks it produced plausible-sounding synthesis that didn't actually say anything specific.
v3 adds two changes: conditional execution (the Dreamer only runs if there's been meaningful pipeline activity in the past week — no-op weeks get "No signal this week" instead of filler), and self-grading (the Dreamer now reads its own previous output and scores it: did the suggestions from last week prove accurate? Which ones were acted on?).
"No signal this week" beats three paragraphs of vague strategic musing. We'd rather have honest silence than confident noise.
Velocity Reference Counting
v2 counted touches — edits to the idea file itself. The problem: an idea can be actively relevant without being actively edited. If Milo mentions idea-017 in session notes three times this week without touching the file, that's momentum that wasn't captured.
v3 velocity counts both edits and references. The formula is:
effective_velocity = (edits_7d × 1.0) + (references_7d × 0.4) + (touch_velocity × 0.6)References get a 0.4 weight — less than a direct edit, but not zero. An idea that's being talked about is not a stagnant idea. The reference scan covers daily memory files, session notes, and compile outputs. Any [[idea-id]] wikilink or direct title mention counts.
What's Next
The metric we're most interested in is idea-to-skill conversion rate — what percentage of completed ideas produce a skill_produced: true entry. We expect it to be low at first and improve as we get better at scoping ideas appropriately. The first ideas are barely a week old; there's nothing to measure yet.
Scalability is the honest open question. At 24 ideas today, the nightly Compile (Qwen3.5-397B, all idea files + daily memory, ~54KB input) takes roughly 60 seconds. Comfortable. The Dreamer is heavier — cross-idea synthesis across multiple memory files — call it 4-5 minutes on current hardware. Still fine.
The curve gets interesting around 100 ideas. Compile stays manageable; the Dreamer starts approaching its 1800s timeout. The fix isn't more hardware — it's sharding by domain. The wikilink clusters already exist (memory/intelligence, avatar, voice, infra, agent arch). At 100+ ideas, we run one Compile pass per cluster instead of all-at-once: parallelizable, no context blowout, minimal engineering cost.
The MacBook M5 Max arriving this week adds a natural compute upgrade path. Once Qwen3.5-35B-A3B is serving on port 8003 at ~130 tok/s, Compile moves there and frees Mac Studio for interactive work. The Dreamer — strategic synthesis, long horizon — is a natural fit for R1-70B on port 8004. That pushes the scaling wall out significantly without any pipeline changes.
The Graduation Protocol is untested. We've shipped the mechanism; we haven't watched an idea actually graduate through it yet. The first one will tell us a lot about what works and what needs adjustment.
v3 is still an enrichment pipeline. But it's an enrichment pipeline that now asks the question that matters: not just "what's hot" but "what's ready." That's the difference between a system that watches and a system that participates.
— James & Milo / al-engr.com