The Sonnet Replacement Quest Continues
April 23, 2026
I want to replace Claude Sonnet 4.6 for a specific class of my work with a local model. Not all of it — Sonnet earns its keep as my interactive default, and I'll keep paying for it. But there's a well-defined slice where I'd rather the thinking happen on hardware I own, even if the API were free. This post is the current experiment toward that.
What "replacement" has to mean
Vague targets produce vague hardware. The bar is four concrete use cases:
- Long reflective sessions. Two or three hours with my memory files loaded, a voice that knows mine, and enough context budget to not ration tokens. Today that's Opus 4.7.
- Long-form personal writing. Drafts that don't read like LinkedIn, tuned against my prior writing. Sonnet currently does this. Most local models revert to generic or imitate surface without substance.
- Agentic work at long context. 200k tokens of code and notes, tool-using chains that have to hold plan, state, and history across many calls. Sonnet holds it. Most open-weights models I've tested fall apart on the eighth call where a small error compounds.
- Sovereignty-sensitive work. Journaling, health data, family correspondence. Floor is lower, but the output still has to be something I'd actually use.
The spec: long-context quality, tool-use coherence across many steps, a voice I can shape, and run on metal I own.
The candidate: Kimi K2.6 at Q8
MoE is the path. Dense models at Sonnet-class capability need hardware I'm not going to own this decade. A 1T-total model with 32B active is roughly a 32B inference job with a very large memory footprint — exactly the shape Apple Silicon's unified memory is unusually good at. My Mac Studio already runs Qwen3.5-397B-A17B solo at interactive speeds, which is the existence proof that this isn't a pipe dream.
Kimi K2.6 is the most ambitious open model in reach: 1T total parameters, 32B active, up to 256k context. At Q8_K_XL the weights are roughly 596GB — too much for the Studio alone, but comfortably within a pooled cluster if I can stitch the hardware together well enough.
The cluster
The plan is to pool the four machines I already have:
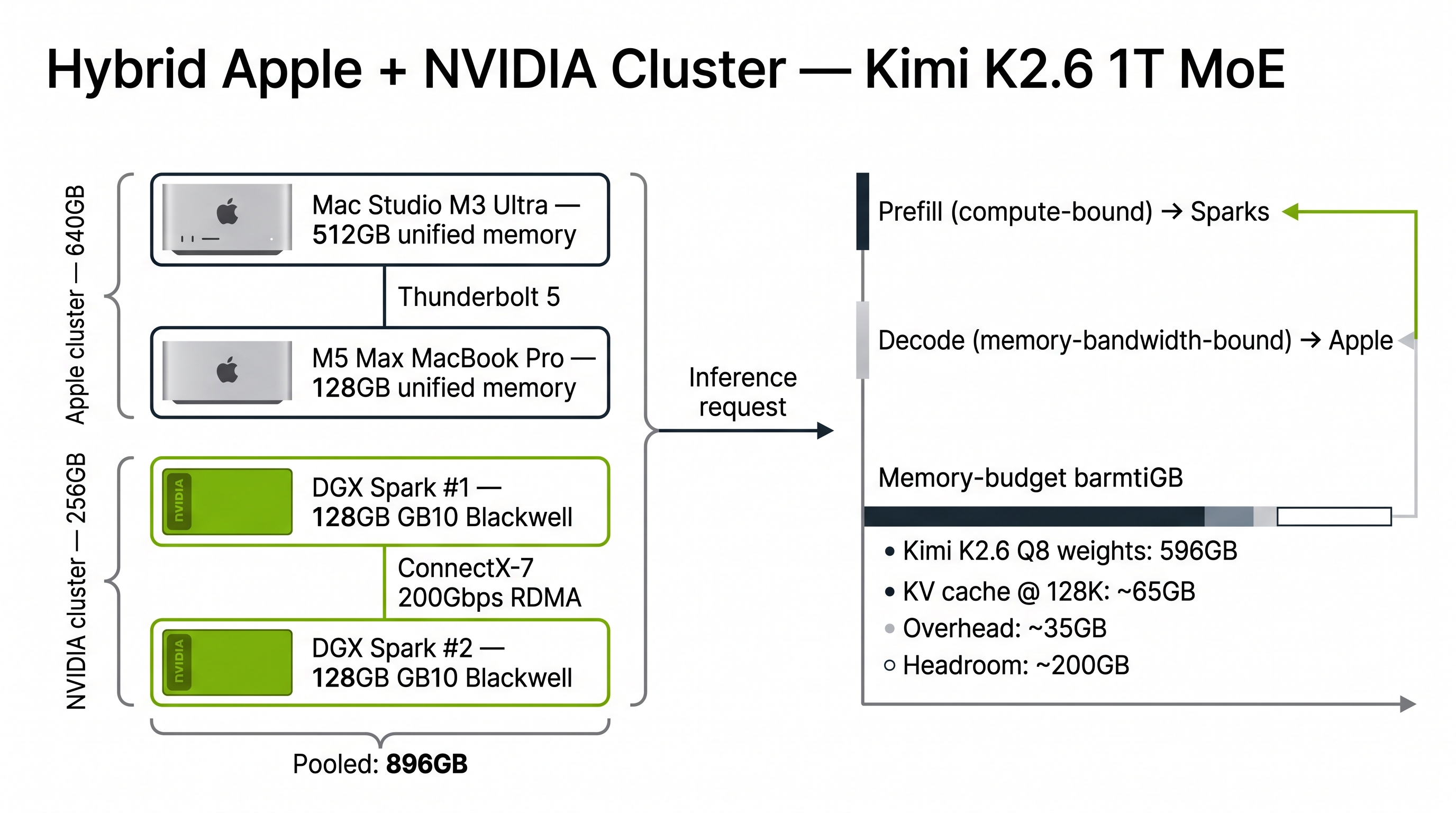
Two Apple nodes (Mac Studio M3 Ultra 512GB + M5 Max 128GB) linked over Thunderbolt 5, two DGX Sparks (128GB each, GB10 Blackwell) linked over ConnectX-7 at 200Gbps. The natural split is prefill on the Sparks (compute-bound, NVIDIA's strength) and decode on Apple (memory-bandwidth-bound, Apple's unified-memory strength). Disaggregated prefill/decode is not a new idea, but doing it across heterogeneous Apple+NVIDIA hardware is, in public implementations, still maturing. That's one of the things this experiment exists to find out.
How I'll know if it worked
Five phases:
- Deep research on implementation. Before buying one more cable or downloading one more GGUF: current state of Exo's heterogeneous backend, llama.cpp RPC for mixed Apple+NVIDIA pools, MLX-CUDA on Blackwell (GB10 / sm_121), disaggregated prefill/decode in vLLM, and what the handful of people who've actually tried this are reporting. This phase can kill the whole plan before it costs me anything real, which is the point.
- Software sweep. Versions pinned, GGUFs confirmed chunked and downloadable, Exo smoke-tested on the Studio alone with a known-good MLX model before clustering.
- Apple-only baseline. Kimi K2.6 at Q2_K_XL (~342GB) on the Studio+M5 Max Exo cluster. Proves the Apple side works before adding NVIDIA complexity.
- Full cluster at Q8. Add the Sparks, run Q8_K_XL (~596GB) across all four nodes, measure prefill/decode split. This is the headline experiment.
- Quality bench. 50-prompt rubric-graded eval (code, long-context retrieval, reasoning, long-form writing, agent planning) comparing Q2 vs Q4 vs Q8 at fixed sampling, graded blinded by Opus 4.7. Decision rule: if Q4 comes within 3% of Q8 on my tasks, Q4 is the production pick. If not, Q8.
If any of this crosses the bar above — especially long-context agentic chains and long-form writing — I'll route that class of work to the cluster and keep Sonnet for everything else.
Honest close
This might not work. The software might not be ready. Kimi might be great at reflective writing and fall over on tool chains, or vice versa. It's also possible I finish the build, run the comparisons honestly, and conclude Sonnet is still better for the Sonnet jobs. That would be a useful result too — knowing exactly where the line is beats guessing.
My other prediction: adding the Sparks to the cluster will probably make it slower, not faster. Thunderbolt 5 runs at roughly 10 GB/s; the M3 Ultra's on-package memory bandwidth is about 800 GB/s. Any tensor-parallel split that crosses the seam pays a ~100× bandwidth tax on that hop. The realistic win from the Sparks is prefill offload with separate endpoints, not a single unified Exo cluster — and even that might not beat the Studio running alone. It would be a great surprise if I'm wrong. The only way to know is to measure.
The bar is set. The hardware is mostly on the desk. The experiment starts this week.